# 标点符号集 stopwords = '''~!@#$%^&*()_+`1234567890-={}[]::";'<>,.?/|\、·!()¥“”‘’《》,。?/—-【】….''' stopwords_set = set([i for i in stopwords]) stopwords_set.add("br") # 异常词也加入此集,方便去除
with open("p_output.txt", "r", encoding="gbk") as f: lines = f.readlines()
# 数据清理 data = [] for line in lines: for s in stopwords_set: line = line.strip().replace(s, "") line = line.replace(" "," ").replace(" "," ") if line != ""and line != " ": data.append(line)
# 保存数据 with open("all.txt", "w", encoding="gbk") as f: f.write(" ".join(data))
with open("dev.txt", "w", encoding="gbk") as f: f.write(dev_text) with open("test.txt", "w", encoding="gbk") as f: f.write(test_text) with open("train.txt", "w", encoding="gbk") as f: f.write(train_text)
classWordEmbeddingDataset(tud.Dataset): def__init__(self, text, word2idx, word_freqs): ''' :text: a list of words, all text from the training dataset :word2idx: the dictionary from word to index :word_freqs: the frequency of each word ''' super(WordEmbeddingDataset, self).__init__() # 注意下面重写的方法 self.text_encoded = [word2idx.get(word, word2idx['<UNK>']) for word in text] # 把单词数字化表示。如果不在词典中,也表示为unk self.text_encoded = torch.LongTensor(self.text_encoded) # nn.Embedding需要传入LongTensor类型 self.word2idx = word2idx self.word_freqs = torch.Tensor(word_freqs)
model = EmbeddingModel(MAX_VOCAB_SIZE, EMBEDDING_SIZE) optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
模型训练和保存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
for e in range(1): for i, (input_labels, pos_labels, neg_labels) in enumerate(dataloader): input_labels = input_labels.long() pos_labels = pos_labels.long() neg_labels = neg_labels.long()
optimizer.zero_grad() loss = model(input_labels, pos_labels, neg_labels).mean() #.mean()默认不设置dim的时候,返回的是所有元素的平均值 loss.backward() optimizer.step() if i % 100 == 0: print('epoch', e, 'iteration', i, loss.item())
deffind_nearest(word): index = word2idx[word] embedding = embedding_weights[index] cos_dis = np.array([scipy.spatial.distance.cosine(e, embedding) for e in embedding_weights]) print(cos_dis.shape) return [idx2word[i] for i in cos_dis.argsort()[:10]]
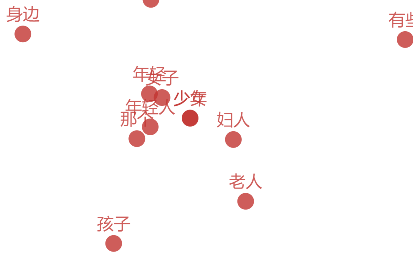
x_data =[] y_data =[] index = 300# 注意我们这里为了防止数据太过密集,只取前300个词来进行绘制 for i, label in enumerate(list(word2idx.keys())[:index]): x, y = float(tsne[i][0]), float(tsne[i][1]) x_data.append(x) y_data.append((y, label))